Project Antalya Concepts Guide
Overview
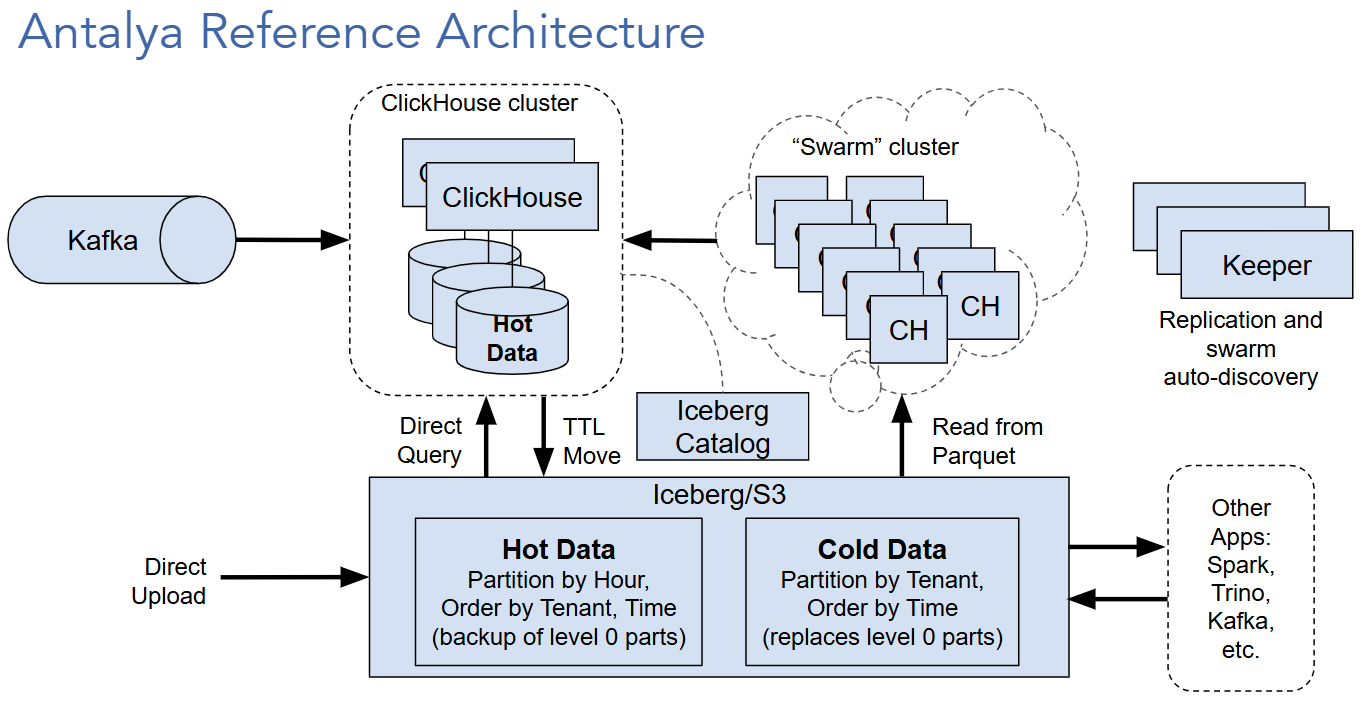
Project Antalya is an extended version of ClickHouse® that offers additional features to allow ClickHouse clusters to use Iceberg as shared storage. The following diagram shows the main parts of a Project Antalya installation:
ClickHouse compatibility
Project Antalya builds are based on upstream ClickHouse and follow ClickHouse versioning. They are drop-in replacements for the matching ClickHouse version. They are built using the same CI/CD pipelines as Altinity Stable Builds.
Iceberg, Parquet, and object storage
Project Antalya includes extended support for fast operation on Iceberg data lakes using Parquet data files on S3-compatible storage. Project Antalya extensions include the following:
- Integration with Iceberg REST catalogs (compatible with upstream ClickHouse)
- Parquet bloom filter support (compatible with upstream ClickHouse)
- Iceberg partition pruning (compatible with upstream ClickHouse)
- Parquet file metadata cache
- Boolean and int type support on native Parquet reader (compatible with upstream ClickHouse)
Iceberg specification support
Generally speaking, Project Antalya’s Iceberg support matches upstream ClickHouse. Project Antalya supports reading Iceberg V2. It cannot write to Iceberg tables. For that you must currently use other tools, such as Spark or pyiceberg.
Altinity also provides the open-source Ice project, a suite of tools that make Iceberg REST catalogs easier to use. See the article Introducing Altinity Ice - A Simple Toolset for Iceberg REST Catalogs on the Altinity blog for an in-depth look at the project, including use cases and sample applications.
There are a number of bugs and missing features in Iceberg support. If you find something unexpected, please log an issue on the Altinity ClickHouse repo. Use one of the Project Antalya issue templates so that the report is automatically tagged to Project Antalya.
Iceberg database engine
The Iceberg database engine encapsulates the tables in a single Iceberg REST catalog. REST catalogs enumerate the metadata for Iceberg tables, and the database engine makes them look like ClickHouse tables. This is the most natural way to integrate with Iceberg tables.
Iceberg table engine and table function
Project Antalya offers Iceberg table engine and functions just like upstream ClickHouse. They encapsulate a single table using the object storage path to locate the table metadata and data. Currently only one table can use the path.
Hive and plain S3
Project Antalya can also read Parquet data directly from S3 as well as Hive format. The capabilities are largely identical to upstream ClickHouse.
Swarm clusters
Project Antalya introduces the notion of swarm clusters, which are clusters of stateless ClickHouse servers that can be used for parallel query as well as (in future) writes to Iceberg. Swarm clusters can scale up and down quickly.
To use a swarm cluster, you must first provision at least one Project Antalya server to act as a query initiator. This server must have access to the table schema, for example by connecting to an Iceberg database using the CREATE DATABASE ... Engine=Iceberg command.
You can dispatch a query on S3 files or Iceberg tables to a swarm cluster by adding the object_storage_cluster = <swarm cluster name>setting to the query. You can also set this value in a profile or as as session setting.
The Project Antalya initiator will parse the query, then dispatch subqueries to nodes of the swarm for query on individual Parquet files. The results are streamed back to the initiator, which merges them and returns final results to the client application.
Swarm auto-discovery using Keeper
Project Antalya uses Keeper servers to implement swarm cluster auto-discovery.
-
Each swarm cluster can register itself in one or more clusters. Each cluster is registered on a unique path in Keeper.
-
Initiators read cluster definitions from Keeper. They are updated as the cluster grows or shrinks.
Project Antalya also supports the notion of an auxiliary Keeper server for cluster discovery. This means that Antalya clusters can use one Keeper ensemble to control replication, and another Keeper server for auto-discovery.
Swarm clusters do not use replication. They only need Keeper for auto-discovery.
Tiered storage between MergeTree and Iceberg
Project Antalya will provide tiered storage between MergeTree and Iceberg tables. Tiered storage includes the following features.
ALTER TABLE MOVEcommand to move parts from MergeTree to external Iceberg tables.TTL MOVEto external Iceberg table. Works as current tiered storage but will also permit different partitioning and sort orders in Iceberg.- Transparent reads across tiered MergeTree / Iceberg tables.
Hybrid tables
One of Project Antalya’s key goals is to manage storage costs. Hybrid tables allow you to query data in tiered storage. Your hot data can be in a MergeTree, with cold data in an Iceberg catalog. Then you can use a single query against all of your data. That can significantly reduce your storage costs without complicating your queries.
The Hybrid table engine lets you specify multiple table segments that are selected by a condition. In this example, the condition is a date:
CREATE TABLE my_hybrid_table AS my_mergetree_table
ENGINE = Hybrid(
cluster('{cluster}', my_mergetree_table),
date >= watermark_date,
my_iceberg_table,
date < watermark_date
)
In this example we have two segments, although you can have more segments for more complex use cases. Data more recent than watermark_date will be in a MergeTree, while older data will be in an Iceberg catalog.
When you run a SELECT against this table, the Hybrid table engine will query the data in all the segments. In addition, the engine will do a simple analysis of the query; for example, if the query contains a WHERE clause on the date that allows the engine to ignore entire segments, it will do so.
Runtime environment
Project Antalya servers can run anywhere ClickHouse runs now. Cloud-native operation on Kubernetes provides a portable and easy-to-configure path for scaling swarm servers. You can also run Antalya clusters on bare metal servers and VMs, just as ClickHouse does today.
Future roadmap
Project Antalya has an active roadmap. Here are some of the planned features:
- Extension of Altinity Backup for ClickHouse to support Project Antalya servers with Iceberg external tables.
- Automatic archiving of level 0 parts to Iceberg so that all data is visible from the time of ingest.
- Materialized views on Iceberg tables.
- Fast ingest using Swarm server. This will amortize the effort of generating Parquet files using cheap compute servers.
There are many more possibilities. We’re looking for contributors. Join the fun!