ClickHouse® High Availability Architecture
The standard approach to ClickHouse® high availability combines replication, backup, and astute service placement to maximize protection against failure of single components and accidental deletion of data.
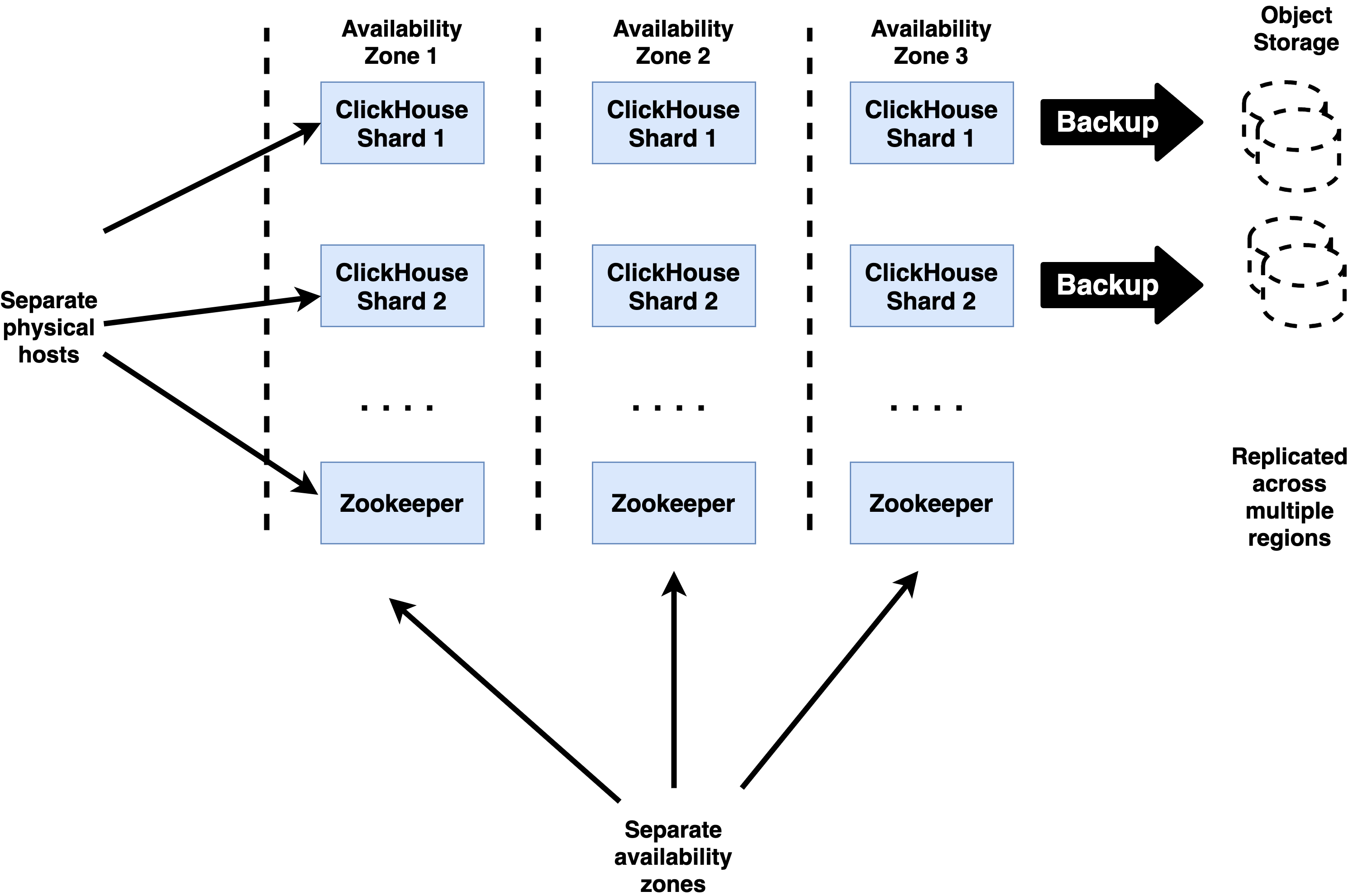
Best Practices for ClickHouse HA
Highly available ClickHouse clusters observe a number of standard practices to ensure the best possible resilience.
Keep at least 3 replicas for each shard
ClickHouse tables should always be replicated to ensure high availability. This means that you should use ReplicatedMergeTree or a similar engine for any table that contains data you want to persist. Cluster definitions for these tables should include at least three hosts per shard.
Having 3 replicas for each ClickHouse shard allows shards to continue processing queries after a replica failure while still maintaining capacity for recovery. When a new replica is attached to the shard it will need to fetch data from the remaining replicas, which adds load.
Use 3 replicas for Zookeeper
Zookeeper ensembles must have an odd number of replicas, and production deployments should always have at least three to avoid losing quorum if a Zookeeper server fails. Losing quorum can cause ClickHouse replicate tables to go into readonly mode, hence should be avoided at all costs. 3 is the most common number of replicas used.
It is possible to use 5 replicas but any additional availability benefit is typically canceled by higher latency to reach consensus on operations (3 vs. 2 servers). We do not recommend this unless there are extenuating circumstances specific to a particular site and the way it manages or uses Zookeeper.
Disperse replicas over availability zones connected by low-latency networks
ClickHouse replicas used for writes and Zookeeper nodes should run in separate availability zones. These are operating environments with separate power, Internet access, physical premises, and infrastructure services like storage arrays. (Most pubic clouds offer them as a feature.) Availability zones should be connected by highly reliable networking offering consistent round-trip latency of 20 milliseconds or less between all nodes. Higher values are likely to delay writes.
It is fine to locate read-only replicas at latencies greater than 20ms. It is important not to send writes to these replicas during normal operation, or they may experience performance problems due to the latency to Zookeeper as well as other ClickHouse replicas.
Locate servers on separate physical hardware
Within a single availability zone ClickHouse and Zookeeper servers should be located on separate physical hosts to avoid losing multiple servers from a single failure. Where practical the servers should also avoid sharing other hardware such as rack power supplies, top-of-rack switches, or other resources that might create a single point of failure.
Use clickhouse-backup to guard against data deletion and corruption
ClickHouse supports backup of tables using the clickhouse-backup utility, which can do both full and incremental backups of servers. Storage in S3 buckets is a popular option as it is relatively low cost and has options to replicate files automatically to buckets located in other regions.
Test regularly
HA procedures should be tested regularly to ensure they work and that you can perform them efficiently and without disturbing the operating environment. Try them out in a staging environment and automate as much as you can.
References for ClickHouse HA
The following links detail important procedures required to implement ClickHouse HA and recovery from failures.
- ClickHouse Data Replication – Overview of ClickHouse replication.
- ClickHouse Recovery After Complete Data Loss – Replace a ClickHouse server that has failed and lost all data.
- Zookeeper Cluster Setup – Describes how to set up a multi-node Zookeeper ensemble. Replacing a failed node is relatively straightforward and similar to initial installation.
- Altinity Backup for ClickHouse – Instructions for performing backup and restore operations on ClickHouse.