ClickHouse® Disaster Recovery Architecture
An optimal approach to disaster recovery builds on the resiliency conferred by the HA best practices detailed in the previous section. To increase the chance of surviving a large scale event that takes out multiple data centers or an entire region, we increase the distance between replicas for ClickHouse® and Zookeeper.
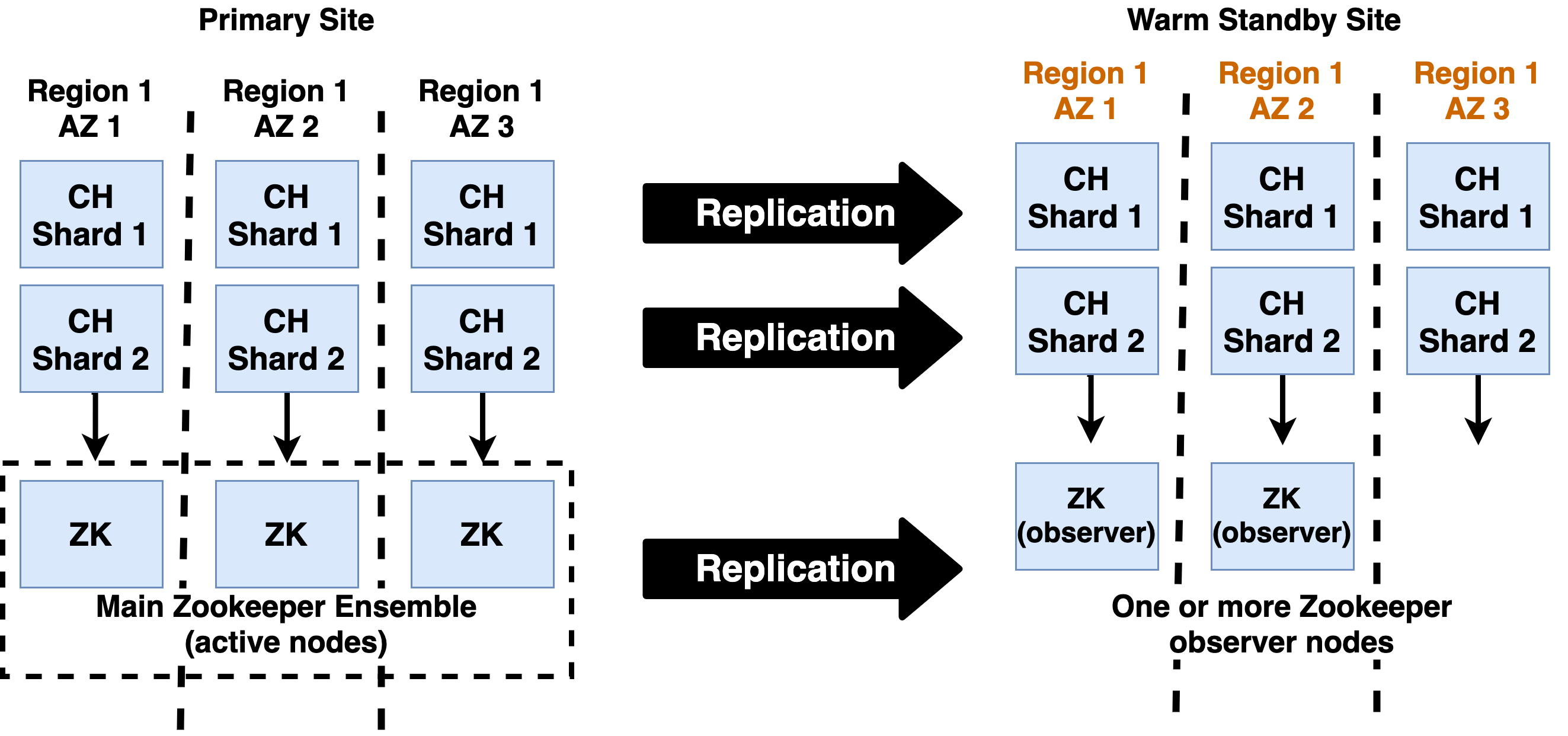
The DR architecture for ClickHouse accomplishes this goal with a primary/warm standby design with two independent clusters. Writes go to a single cluster (the primary site), while the other cluster receives replicated data and at most is used for reads (the warm standby site). The following diagram shows this design.
Best Practices for ClickHouse DR
Point all replicas to main Zookeeper ensemble
ClickHouse replicas on both the primary and warm standby sites should point to the main Zookeeper ensemble. Replicas in both locations can initiate merges. This is generally preferable to using cross-region transfer which can be costly and consumes bandwidth.
Send writes only to primary replicas
Applications should write data only to primary replicas, i.e., replicas with a latency of less than 20ms to the main Zookeeper ensemble. This is necessary to ensure good write performance, as it is dependent on Zookeeper latency.
Reads may be sent to any replica on any site. This is a good practice to ensure warm standby replicas are in good condition and ready in the event of a failover.
Run Zookeeper observers on the warm standby
Zookeeper observers receive events from the main Zookeeper ensemble but do not participate in quorum decisions. The observers ensure that Zookeeper state is available to create a new ensemble on the warm standby. Meanwhile they do not affect quorum on the primary site. ClickHouse replicas should connect to the main ensemble, not the observers, as this is more performant.
Depending on your appetite for risk, a single observer is sufficient for DR purposes. You can expand it to a cluster in the event of a failover..
Use independent cluster definitions for each site
Each site should use independent cluster definitions that share the cluster name and number of shards but use separate hosts from each site. Here is an example of the cluster definitions in remote_servers.xml on separate sites in Chicago and Dallas. First, the Chicago cluster definition, which refers to Chicago hosts only .
<!-- Chicago Cluster Definition -->
<yandex>
<remote_servers>
<cluster1>
<shard>
<replica>
<host>chi-prod-01</host>
<port>9000</port>
</replica>
<replica>
. . .
</shard>
<shard>
. . .
</shard>
</cluster1>
</remote_servers>
</yandex>
Next, we have the Dallas cluster definition. As you can see here the definitions are identical except for host names.
<!-- Dallas Cluster Definition -->
<yandex>
<remote_servers>
<cluster1>
<shard>
<replica>
<host>dfw-prod-01</host>
<port>9000</port>
</replica>
<replica>
. . .
</shard>
<shard>
. . .
</shard>
</cluster1>
</remote_servers>
</yandex
This definition ensures that distributed tables will only refer to tables within a single site. This avoids extra latency if subqueries go across sites. It also means the cluster definition does not require alteration in the event of a failover..
Use “Umbrella” cluster for DDL operations
For convenience to perform DDL operations against all nodes you can add one more cluster and include all ClickHouse nodes into this cluster. Run ON CLUSTER commands against this cluster. The following “all” cluster is used for DDL.
<!-- All Cluster Definition -->
<yandex>
<remote_servers>
<all>
<shard>
<replica>
<host>dfw-prod-01</host>
<port>9000</port>
</replica>
<replica>
<host>chi-prod-01</host>
<port>9000</port>
</replica>
</shard>
<shard>
. . .
</shard>
</all>
</remote_servers>
</yandex>
Assuming the ‘all’ cluster is present on all sites you can now issue DDL commands like the following.
CREATE TABLE IF NOT EXISTS events_local ON CLUSTER all
...
;
Use macros to enable replication across sites
It is a best practice to use macro definitions when defining tables to ensure consistent paths for replicated as distributed tables. Macros are conventionally defined in file macros.xml. The macro definitions should appear as shown in the following example. (Names may vary of course.)
<yandex>
<macros>
<!-- Shared across sites -->
<cluster>cluster1</cluster>
<!-- Shared across sites -->
<shard>0</shard>
<!-- Replica names are unique for each node on both sites. -->
<replica>chi-prod-01</replica>
</macros>
</yandex>
The following example illustrates usage of DDL commands with the previous macros. Note that the ON CLUSTER clause uses the ‘all’ umbrella cluster definition to ensure propagation of commands across all sites.
-- Use 'all' cluster for DDL.
CREATE TABLE IF NOT EXISTS events_local ON CLUSTER 'all' (
event_date Date,
event_type Int32,
article_id Int32,
title String
.
ENGINE = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/{database}/events_local', '{replica}')
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_type, article_id);
CREATE TABLE events ON CLUSTER 'all' AS events_local
ENGINE = Distributed('{cluster}', default, events_local, rand())
Using this pattern, tables will replicate across sites but distributed queries will be restricted to a single site due to the definitions for cluster1 being different on different sites.
Test regularly
It is critical to test that warm standby sites work fully. Here are three recommendations.
- Maintain a constant, light application load on the warm standby cluster including a small number of writes and a larger number of reads. This ensures that all components work correctly and will be able to handle transactions if there is a failover.
- Partition networks between sites regularly to ensure that the primary works properly.
- Test failover on a regular basis to ensure that it works well and can be applied efficiently when needed.
Monitoring
Replication Lag
Monitor ClickHouse replication lag/state using HTTP REST commands.
*curl http://ch_host:8123/replicas_status.
Also, check the absolute_delay from **system.replication_status **table.
Zookeeper Status
You can monitor the ZK ensemble and observers using: **echo stat | nc <zookeeper ip> 2181
Ensure that servers have the expected leader/follower and observer roles. Further commands can be found in the Zookeeper administrative docs.
Heartbeat Table
Add a service heartbeat table and make inserts at one site and select at another. It gives an additional check of replication status / lag across systems.
create table heart_beat(
site_id String,
updated_at DateTime .
Engine = ReplicatedReplacingMergeTree(updated_at.
order by site_id;
-- insert local heartbeat
insert into heart_beat values('chicago', now()); .
-- check lag for other sites
select site_id.
now() - max(updated_at) lag_seconds
from heart_beat
where site_id <> 'chicago'
group by site_id
References for ClickHouse DR
The following links detail important information required to implement ClickHouse DR designs and implement disaster recovery procedures..
- Zookeeper Observers – Procedure to set up and manage a Zookeeper observer.
- Zookeeper Dynamic Reconfiguration – Procedures to modify ensembles, promote observers, etc.
Failover and Recovery from Disasters
Failures in a DR event are different from HA. Switching to the warm standby site typically requires an explicit decision for the following reasons:
- Moving applications to the standby site requires changes across the entire application stack from public facing DNS and load balancing downwards..
- Disasters do not always affect all parts of the stack equally, so switching involves a cost-benefit decision. Depending on the circumstances, it may make sense to limp along on the primary.
It is generally a bad practice to try to automate the decision to switch sites due to the many factors that go into the decision as well as the chance of accidental failover. The actual steps to carry out disaster recovery should of course be automated, thoroughly documented, and tested.
Failover
Failover is the procedure for activating the warm standby site. For the ClickHouse DR architecture, this includes the following steps.
- Ensure no writes are currently being processed by standby nodes.
- Stop each Zookeeper server on the standby site and change the configuration to make them active members in the ensemble..
- Restart Zookeeper servers.
- Start additional Zookeeper servers as necessary to create a 3 node ensemble.
- Configure ClickHouse servers to point to new Zookeeper ensemble.
- Check monitoring to ensure ClickHouse is functioning properly and applications are able to connect.
Recovering the Primary
Recovery restores the primary site to a condition that allows it to receive load again. The following steps initiate recovery.
- Configure the primary site Zookeepers as observers and add server addresses back into the configuration on the warm standby site.
- Restart Zookeepers as needed to bring up the observer nodes. Ensure they are healthy and receiving transactions from the ensemble on the warm standby site.
- Replace any failed ClickHouse servers and start them using the procedure for recovering a failed ClickHouse node after full data loss.
- Check monitoring to ensure ClickHouse is functioning properly and applications are able to connect. Ensure replication is caught up for all tables on all replicas.
- Add load (if possible) to test the primary site and ensure it is functioning fully.
Failback
Failback is the procedure for returning processing to the primary site. Use the failover procedure in reverse, followed by recovery on the warm standby to reverse replication.
Cost Considerations for DR
Disasters are rare, so many organizations balance the cost of maintaining a warm standby site with parameters like the time to recover or capacity of the warm standby site itself to bear transaction load. Here are suggestions to help cut costs.
Use fewer servers in the ClickHouse cluster
It is possible to reduce the number of replicas per shard to save on operating costs. This of course raises the chance that some part of the DR site may also fail during a failover, resulting in data loss.
Use cheaper hardware
Using less performant hardware is a time-honored way to reduce DR costs. ClickHouse operates perfectly well on slow disk, so storage is a good place to look for savings, followed by the hosts themselves.
Host DR in the public cloud
ClickHouse and Zookeeper both run well on VMs so this avoids costs associated with physical installations (assuming you have them). Another advantage of public clouds is that they have more options to run with low-capacity hardware, e.g., by choosing smaller VMs.
Use network attached storage to enable vertical scaling from minimal base
ClickHouse and Zookeeper run well on network attached storage, for example Amazon EBS. You can run the warm standby site using minimum-sized VMs that are sufficient to handle replication and keep storage updated. Upon failover you can allocate more powerful VMs and re-attach the storage..
Caveat: In a large-scale catastrophe it is quite possible many others will be trying to do the same thing, so the more powerful VMs may not be available when you need them.
Discussion of Alternative DR Architectures
Primary/warm standby is the recommended approach for ClickHouse DR. There are other approaches of course, so here is a short discussion.
Active-active DR architectures make both sites peers of each other and have them both running applications and full load. As a practical matter this means that you would extend the Zookeeper ensemble to multiple sites. The catch is that ClickHouse writes intensively to Zookeeper on insert, which would result in high insert latency as Zookeeper writes across sites. Products that take this approach put Zookeeper nodes in 3 locations, rather than just two. (See an illustration of this design from the Confluent documentation.)
Another option is storage-only replication. This approach replicates data across sites but does not activate database instances on the warm standby site until a disaster occurs. Unlike Oracle or PostgreSQL, ClickHouse does not have a built-in log that can be shipped to a remote location. It is possible to use file system replication, such as Linux DRBD, but this approach has not been tested. It looks feasible for single ClickHouse instances but does not seem practical for large clusters.